
사용자:Regpath/연습장/초안/주의 기제
본문[편집]
| 기계 학습과 데이터 마이닝 |
|---|
 |
신경망에서 주의 기제는 인지심리학에서의 주의를 모방하여 고안된 기술이다. 주의기제는 네트워크가 데이터 중에 비중이 적지만 중요한 데이터에 더 집중하기 위하여, 입력 데이터 중 일부의 효과를 증강시키며, 다른 일부를 감소시킨다. 데이터 중 어느 부분을 학습하는 것이 다른 부분을 학습하는 것보다 더 중요한지는 문맥에 따라 결정되며, 이는 경사하강법으로 학습된다.
어텐션과 같은 메커니즘은 1990년대에 곱셈 모듈, 시그마 파이 단위, 또는 하이퍼네트워크와 같은 이름으로 도입되었다. 주의 기제의 유연성은 런타임 도중에 변경될 수 있는 '소프트 가중치'로서의 역할에서 온다. 런타임 동안 고정되어 있는 표준 가중치와는 달리.
주의 기제는 뉴럴 튜링 머신의 기억, 미분가능 뉴럴 컴퓨터의 추론 작업, 트랜스포머 계열 모델의 언어 처리, 지각자(perceiver)의 다중 감각 데이터 처리 (소리, 이미지, 영상, 텍스트) 등에 활용된다.
개요[편집]
인덱스 가 붙은 일련의 토큰이 주어졌을 때, 신경망은 각 토큰에 대하여 음수가 아니며 인 소프트 가중치 를 계산한다.각 토큰에는 번째 토큰의 단어 임베딩으로부터 계산된 값 벡터가 할당된다. 가중 평균 이 주의 기제의 출력이다.




쿼리-키 메커니즘은 소프트 가중치를 계산한다. 각 토큰의 단어 임베딩으로부터 쿼리 벡터 와 키 벡터 가 계산된다. 가중치는 내적 의 소프트맥스 함수를 취하여 얻는다. 여기서 는 현 토큰, 는 주의가 기울여지는 토큰을 나타낸다.




일부 아키텍처에는, 각각의 고유한 쿼리, 키, 값으로 독립적으로 작동하는 여러 개의 주의 헤드(attention head)가 있다.
언어 번역 예[편집]
영어를 프랑스어로 번역하는 기계를 만들려면 기본 Encoder-Decoder를 사용하고 여기에 주의 단위를 접목한다 (아래 다이어그램). 가장 간단한 경우 주의 단위는 반복 인코더 상태의 내적으로 구성되며 훈련이 필요하지 않다. 실제로, 어텐션 유닛은 훈련이 필요한 쿼리-키-값(query-key-value)이라고 하는 3개의 완전히 연결된 신경망 레이어로 구성된다. 아래의 변형 섹션을 참조하라.
|
Click here for the static image: File:Attention-1-sn.png | ||||||||||||||||||||||||||||||||
|
행렬로 볼 때 주의 가중치는 네트워크가 컨텍스트에 따라 초점을 조정하는 방법을 보여ㅜㄴ다.
| I | love | you | |
| je | 0.94 | 0.02 | 0.04 |
| t' | 0.11 | 0.01 | 0.88 |
| aime | 0.03 | 0.95 | 0.02 |
주의 가중치에 대한 이러한 관점은 신경망이 비판받는 "설명 가능성" 문제를 해결한다. 단어 순서에 관계 없이 축어 번역을 수행하는 네트워크는 이러한 용어로 분석할 수 있는 경우 대각선으로 지배적인 행렬을 갖게 된다. 비대각선 우성은 주의 메커니즘이 더 미묘하다는 것을 보여준다. 디코더를 통한 첫 번째 통과에서 주의 가중치의 94%는 첫 번째 영어 단어 "I"에 있으므로 네트워크는 단어 "je"를 제공한다. 디코더의 두 번째 패스에서 주의 가중치의 88%는 세 번째 영어 단어 "you"에 있으므로 "t'"를 제공한다. 마지막 패스에서는 주의 가중치의 95%가 두 번째 영어 단어 "love"에 있으므로 "aime"을 제공한다.
변형[편집]
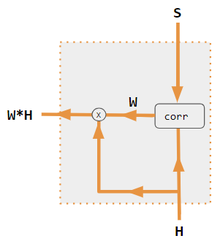
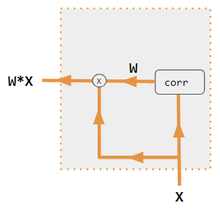
주의에는 내적, 쿼리 키-값, hard, soft, self, cross, Luong, 및 Bahdanau 와 같이 많은 변형이 있다. 이러한 변형은 인코더 측 입력을 재결합하여 해당 효과를 각 대상 출력에 재분배한다. 종종 상관 스타일의 내적 행렬은 다시 가중치를 부여하는 계수를 제공한다(범례 참조).
| 1. 인코더-디코더 내적 | 2. 인코더-디코더 QKV | 3. 인코더 전용 내적 | 4. 인코더 전용 QKV | 5. 파이토치 튜토리얼 |
|---|---|---|---|---|
 |
 |
 |
 |
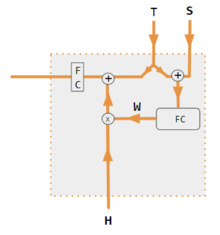 |
| 상표 | 설명 |
|---|---|
| 변수 X, H, S, T | 대문자 변수는 현재 단어뿐만 아니라 전체 문장을 나타낸다. 예를 들어, H는 인코더 은닉 상태의 행렬(열당 하나의 단어)이다. |
| 성 | S, 디코더 은닉 상태; T, 대상 단어 임베딩. Pytorch Tutorial 변형 교육 단계에서 T는 사용된 교사 강제 수준에 따라 2개의 소스를 번갈아 사용한다. T는 네트워크의 출력 단어의 임베딩일 수 있다. 즉, embedding(argmax(FC output))이다. 또는 교사 강제를 사용하여 T는 1/2과 같이 일정한 강제 확률로 발생할 수 있는 알려진 올바른 단어의 포함일 수 있다. |
| X, H | H, 인코더 숨겨진 상태; X, 입력 단어 임베딩. |
| 여 | 주의 계수 |
| Qw, Kw, Vw, FC | 쿼리, 키, 벡터 각각에 대한 가중치 행렬이다. FC는 완전히 연결된 가중치 행렬이다. |
| 동그라미 친 +, 동그라미 x | 원으로 표시된 +, 벡터 연결; 동그라미 x, 행렬 곱셈. |
| 코르 | 열별 softmax(내적의 모든 조합의 행렬). 내적은 변형 #3의 x i * x j, 변형 1 의 h i * s j, 변형 2의 i 열( Kw* H )* j 열( Qw* S ) 및 i 열(Kw* X)입니다. )* 변형 4의 열 j (Qw* X). 변형 5는 완전 연결 계층을 사용하여 계수를 결정한다. 변형이 QKV인 경우 내적은 sqrt(d)에 의해 정규화되며 여기서 d는 QKV 행렬의 높이이다. |
같이 보기[편집]
- Transformer (machine learning model) § Scaled dot-product attention
- Perceiver § Components for query-key-value (QKV) attention
References[편집]
인용 오류: <references> 안에 정의된 "pytorch_s2s"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "Lecun2020"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "Graves2016"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "allyouneed"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "Ramachandran2019"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "jaegle2021"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "tiernan2021"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "xy-dot"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "xy-qkv"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "xx-dot"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "xx-qkv"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "pytorch-tutorial"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
<references> 안에 정의된 "Bahdanau"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.참고문헌[편집]
인용 오류: <references> 안에 정의된 "pytorch_s2s"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "Lecun2020"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "Graves2016"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "allyouneed"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "Ramachandran2019"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "jaegle2021"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "tiernan2021"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "xy-dot"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "xy-qkv"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "xx-dot"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "xx-qkv"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
인용 오류: <references> 안에 정의된 "pytorch-tutorial"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.
<references> 안에 정의된 "Bahdanau"이라는 이름을 가진 <ref> 태그가 위에서 사용되고 있지 않습니다.외부 링크[편집]
- Dan Jurafsky 및 James H. Martin (2022) 음성 및 언어 처리 (3rd ed. draft, 2022년 1월), ch. 10.4 주의 및 ch. 9.7 자기 주의 네트워크: 변압기
- Alex Graves (2020년 5월 4일), 딥 러닝의 주의 및 기억 (비디오 강의), DeepMind / UCL, YouTube를 통해
- Rasa 알고리즘 화이트보드 - YouTube를 통한 주의
틀:Differentiable computing [[분류:기계 학습]]